
脑裂(Split Brain)
多控制节点难以完全避免脑裂问题。早期解决脑裂问题的方案有:
- 构建不可能出现问题的网络。使用大量资金搭建物理环境,将故障概率尽可能降低。
- 人工解决问题。当控制节点部分下线时等待人为决策。
过半票决
使用奇数个服务器,确保当网络被分割为两边时,总有一边服务器较多。在任何时候为了完成任何操作,都必须经过过半服务器批准相应操作。
“过半服务器”指超过服务器总数的一半,而不是开机服务器的一半。若系统中有个服务器,则系统最多可以接受 F 个服务器出现故障,依然可以正常工作。
这种系统称为“多数投票系统”。它们还有个重要特性是“任意两组过半服务器,至少有一个服务器是重叠的”,这确保新的一组过半服务器中,至少有一个服务器存有旧Raft Leader信息。这是避免脑裂的根本保证。
Raft初探
Raft以库的形式存在于服务中,可以认为Raft节点的上层是应用程序代码,应用程序对Raft层进行函数调用来传递自己的状态和Raft反馈的信息;Raft层负责帮助应用程序将其状态拷贝到其他副本节点。Raft本身也会保存状态,记录操作的日志。
客户端总是将请求发给当前Raft集群的Leader,在程序内部,应用将请求对应的操作发送到Raft层,要求Raft层将操作提交到所有副本的日志中。Raft节点间互相交互,直到过半Raft节点将这个新的操作加入日志。Leader节点得知已有过半节点存储了这个操作的拷贝后,告知应用程序真正执行操作。
Leader节点最终真正完成操作后,每个副本节点的Raft再将相同的操作提交到应用程序层。理想情况下,所有副本都将进行相同的操作序列。
Log同步时序
以一个3节点的KV存储系统为例。
Raft内部的工作方式:
- 客户端将请求发送给Leader,假设这是一个简单的Put请求。
- Leader的Raft层发送“添加日志(AppendEntries)”的RPC到其他两个副本,然后等待副本的响应。
- 一旦过半节点响应(该3节点集群中只需要等待1个副本节点的响应),Leader将正式执行来自客户端的请求,得到执行结果,并将结果返回给客户端。
- 在Leader的下一次AppendEntries RPC中,夹带已提交(committed)最大日志序号,副本收到后即可得知此前的日志已被Leader提交,同步执行相应请求。
commit消息伴随AppendEntries消息发出的设计,会导致副本与Leader的同步不太及时。对于客户端请求频繁的场景,同步时延可能不大;但请求稀疏的情况下,或许需要Leader发送心跳包或特殊的AppendEntries消息来维持同步。 不过在不出错的时候,副本执行客户端请求的时机不太重要,因为并没有某方等待副本执行结果,不会影响客户端的感受。
日志(Raft Log)
Log是Leader对操作排序的手段,对复制状态机来说至关重要。对副本(Follower)来说,收到操作但还未执行操作时,Follower需要Log存放临时操作。对Leader来说,Leader需要使用Log来记录操作,因为在Follower短时间离线或丢失消息时,这些操作需要重传给Follower。即使是那些已经commit的请求,也需要存储在Leader的Log中。
所有节点都需要保存Log,还因为重启服务器时需要使用Log恢复状态。所有服务器都将Log写入磁盘,若故障重启,则会从头执行Log从而重建故障前的状态。
考虑Follower执行操作速率始终低于Leader的情况。Log将在Follower中无限堆积,最终导致内存耗尽。所以实际系统中需要额外通信来把Follower的执行情况通知给Leader,从而调节Leader执行速度。
Follower的commit进度始终受Leader调控。服务器刚故障重启时必然是Follower,由于并不清楚哪些Log被commit过,它只会读取所有Log而不执行任何操作,直到收到Leader提供的committed信息。
考虑极端情况,所有服务器一起出现故障并重启。此时将进行Leader选举选出一个Leader,Leader将在第一次心跳时确认系统执行到哪一步:Leader确认出过半服务器认可的最近Log执行点。然后Leader迫使所有Follower的Log与自己一致,并确认commit序号。所有节点基于该序号从头执行所有log。
应用层接口
在Raft集群中的每个节点上,应用程序层和Raft层间主要有两个接口:
- 应用程序转发客户端请求到Raft的接口
当应用程序接收到客户端请求时,应用程序将请求转发到Raft层,令其将请求存放到Log中,并需要Raft在committed后通知应用程序。可以将其抽象为参数为客户端请求的Start函数调用。
Start函数应返回请求在Log中存放的index和当前leader任期号(term number)等信息,以将Raft层的通知与请求对应起来。 - Raft层通知应用程序请求committed的接口
Raft通知的committed请求不一定是最近Start函数传入的请求。为实现消息异步处理,这里应当使用异步消息Channel。消息应包含请求和Log index。
直到应用程序收到Raft层的commited通知时,应用程序才能向客户端发送响应,这样方能确保日志与服务端行为一致。若设定应用程序在Start返回时响应,但它在Start返回瞬间故障,这条日志是不应被commit的。
对于Raft,不同副本的Log存在差异是常有的情况。因此需要Leader Election机制强制确认所有副本的Log保持一致。
Leader选举(Leader Election)
通过一组服务器共同认同Log的顺序,则不用Leader也可以构建一个类似的分布式系统。但Leader的存在可以使整个系统更高效:只需通过一轮消息就能获得过半服务器认可;而不需要像常见的无Leader系统一样先用一轮消息确认临时Leader。
Raft生命周期中使用任期号(Term Number)区分当前Leader,而不需要知道Leader的ID。每个任期最多有一个Leader(没有Leader或有一个)。
- 每个Raft节点维护一个选举定时器(Election Timer)。定时器时间耗尽前,若当前节点未收到任何当前Leader的消息,则认定Leader下线,发起一次选举。
- “发起选举”的含义是当前服务器增加任期号,并尝试成为新的Leader,向其他所有Raft节点(N-1个)发送请求投票(RequestVote)RPC。而当前服务器作为Leader的候选人,它总会投票给自己。
选举机制能保证Leader发生故障且有其他服务器存活时,总会有服务器发起选举。但并不能确保发起选举时,Leader的确出现了故障。
例如,网络故障导致分区,旧Leader和少数Follower位于一个分区,而另一个分区的服务器选出了新Leader。此时就出现了问题:
客户端向旧Leader发送请求,旧Leader发送AppendEntries后永远无法获得过半服务器的回应,所以它不会commit请求,也不会执行请求或响应客户端。对于这些客户端来说,整个Raft系统看似完全故障了。
还有一个潜在的问题:Leader在向部分Follower发送AppendEntries消息后故障,Leader尚未决定Commit这个请求,而部分节点已将请求放入Log。
在极端情况下,例如Leader向Followers和客户端的网络单向可达,则系统不会进行Leader选举,但Leader又无法接收客户端发来的请求,导致整个系统无法处理请求。不过这个问题可以通过双向心跳解决。
Leader选举确认每个任期内最多只有一个Leader的方式是:对于任意一个任期,每个节点只会对一个候选人投一次票,且只有获得过半服务器选票的节点能成为Leader。少数服务器故障时,可以确保选出单个Leader;而过半服务器故障时,系统不可能选出Leader。
当某个服务器赢得选举时,会立刻向所有服务器发送一条特殊的AppendEntries消息。Raft规定,只有当前任期的Leader能发送AppendEntries消息,而AppendEntries消息携带源Leader的任期号。节点通过这条消息得知新Leader被选出。
选举定时器(Election Timer)
接收任何一条AppendEntries消息都会重置当前节点的选举定时器。在网络正常的情况下,Leader心跳和其他AppendEntries消息可以阻止新选举。
如果某次选举没有选出Leader,这次选举就失败了,这时不会有任何特殊处理,静待某个节点再次发起选举。
在节点均正常工作的情况下,也有可能发生选票分割(Split Vote)而无法选出Leader:多个节点计时器同时超时而同时发起选举,它们都将投票给自己,导致没有节点获得过半选票。因此,选举定时器的超时时间应在一定范围内随机选择,避免连续触发选票分割。
随机超时时间的下界显然是Leader心跳间隔的几倍。上界决定了系统最快的故障恢复时间,并要确保不同节点的超时时间差足够长,需要根据故障频率、节点通信时间等综合考虑。
异常场景
在旧Leader故障后,新Leader如何整理不同副本上可能不一致的Log?
可能存在这样的异常情况:
简单的不一致情况
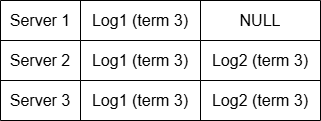
- 发送给Server1的消息丢了
- Server1当时已经关机了
- Server3在向Serve2发送完AppendEntries之后,在向Server1发送AppendEntries之前故障了
若此时Leader Server3故障,从新Leader的视角来看,Log2的请求可能已被commit了,不能随便丢弃。新Leader还要确保Server1也记录Log2。
复杂些的不一致情况
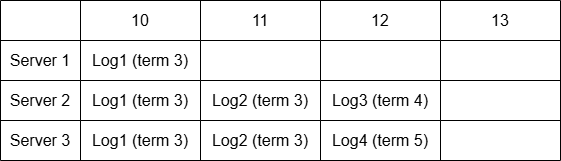
在简单的不一致情况基础上,若任期4时Server2作为Leader,将Log3加入自身Log后就故障了;之后Server3被选为Leader,将Log4加入自身Log后就故障了,便出现了这种异常情况。此时Log1和Log2已被写入过半节点,新Leader无法确认是否它们被commit过,所以不能丢弃,必须假定它们已经被commit。而Log3和Log4没有被过半节点记录,可以选择丢弃它们,且至少要丢弃一个才能保持多个副本间的一致性。



原来这些术语有这么多形象的类比(๑>ڡ<)✿
设计灵感来自生活嘛|´・ω・)ノ
支持增殖的misaka
做不出上次的课堂作业有惩罚哦
😰