
MapReduce框架旨在简化并行的大规模分布式运算程序的编写。使用者只需提供Map和Reduce函数,MapReduce框架内部即可处理其他细节。
- 框架由单个Coordinator进程和数个Worker进程组成。框架读取文件输入。
- Reduce函数接收某些键的键值对作为输入,按需返回结果。
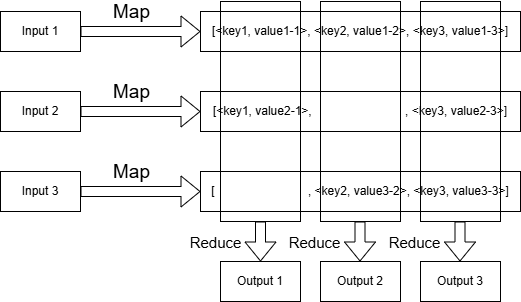
Map函数与Reduce函数
标准的Map函数将文件名和文件内容作为输入,返回若干键值对。
例如,在词频统计任务中,Map函数接收要统计词频的文本,输出若干 <word, 1> 。
func Map(filename string, contents string) []mr.KeyValue {
// function to detect word separators.
ff := func(r rune) bool { return !unicode.IsLetter(r) }
// split contents into an array of words.
words := strings.FieldsFunc(contents, ff)
kva := []mr.KeyValue{}
for _, w := range words {
kv := mr.KeyValue{w, "1"}
kva = append(kva, kv)
}
return kva
}标准的Reduce函数接收若干键相同的键值对,返回所需计算结果。例如,在词频统计任务中,Reduce函数接收键为某个单词的所有键值对,返回这个单词的出现次数。
func Reduce(key string, values []string) string {
// return the number of occurrences of this word.
return strconv.Itoa(len(values))
}本质上,Map函数对原始数据进行分组,为单个Reduce函数负责处理的一系列数据分配相同的键;Reduce函数中按键将数据分组处理。显然需要等待Map任务全部完成后才能开始Reduce任务。
MapReduce框架
MapReduce框架中,单个Coordinator进程负责协调若干Worker工作,Worker根据Coordinator提供的参数进行Map或Reduce任务。
示例代码中Coordinator与Worker为同一主机上的不同进程,通过RPC通讯,且可以直接读写本地文件。实际情况中,Coordinator与Worker也可以通过http等多种方式通讯,并通常借助AFS等文件系统共享文件。
Part1 初始化Coordinator服务&启动Worker进程
Coordinator作为RPC服务器接收Worker请求。Coordinator应指定Reduce任务数量,便于后续使用 hash( key ) % NReduce 将键值对分组存储。
type MapTaskState struct {
File string
Status Status
StartTime time.Time
}
type ReduceTaskState struct {
Status Status
StartTime time.Time
}
type Coordinator struct {
rwMux sync.RWMutex
NReduce int
MapTaskRecord []MapTaskState
mapTasksFinished int
ReduceTaskRecord []ReduceTaskState
reduceTaskFinished int
}
// ...
func MakeCoordinator(sockname string, files []string, nReduce int) *Coordinator { // 在创建Coordinator时完成任务安排,便于后续分配
c := Coordinator{}
c.rwMux = sync.RWMutex{}
c.MapTaskRecord = make([]MapTaskState, len(files))
for i, f := range files { // 初始化Map任务,每个Map任务需要读取特定,故需存储文件名
c.MapTaskRecord[i] = MapTaskState{
File: f,
Status: WAITING,
}
}
c.mapTasksFinished = 0
c.ReduceTaskRecord = make([]ReduceTaskState, nReduce)
for i := range c.ReduceTaskRecord { // 初始Reduce任务
c.ReduceTaskRecord[i] = ReduceTaskState{
Status: WAITING,
}
}
c.reduceTaskFinished = 0
c.NReduce = nReduce
c.server(sockname)
return &c
}
// start a thread that listens for RPCs from worker.go
func (c *Coordinator) server(sockname string) {
rpc.Register(c)
rpc.HandleHTTP()
os.Remove(sockname)
l, e := net.Listen("unix", sockname)
if e != nil {
log.Fatalf("listen error %s: %v", sockname, e)
}
go http.Serve(l, nil)
}Worker则是一个包含事件循环的函数,将Map函数和Reduce函数作为参数。
func Worker(sockname string, mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
coordSockName = sockname
for {
msg := &AssignMessage{}
var emptyArg AssignTaskArgs
if ok := call("Coordinator.AssignTask", &emptyArg, msg); !ok {
log.Println("Coordinator exit")
return
}// 每次循环,Worker向Coordinator请求任务
switch msg.Task {
case EXIT: // Worker退出
return
case WAIT: // Worker等待
time.Sleep(1 * time.Second)
case MAP: // 执行Map任务
file, err := os.Open(msg.Info) // Coordinator传参输入文件名
if err != nil {
return
}
data, err := io.ReadAll(file)
file.Close()
if err != nil {
return
}
kvs := mapf(msg.Info, string(data)) // 执行Map函数,输出键值对
buckets := make([][]KeyValue, msg.NReduce)
for _, kv := range kvs {
index := ihash(kv.Key) % msg.NReduce // 使用hash(key) % NReduce将键值对分组存储
buckets[index] = append(buckets[index], kv)
}
for idx, buff := range buckets { // 分桶完成后写入文件
filename := fmt.Sprintf("mr-intermediate-%d-%d", msg.Id, idx)
tmp, err := os.CreateTemp(".", "tmp-mr-*") // 先创建temp文件,写入完成后重命名,避免暴露不完整文件
if err != nil {
log.Println("map write failed: ", err)
}
encoder := json.NewEncoder(tmp)
for _, kv := range buff {
if err := encoder.Encode(kv); err != nil { // json存储便于读取
log.Println("map write encode failed: ", err)
tmp.Close()
return
}
}
tmp.Close()
err = os.Rename(tmp.Name(), filename)
if err != nil {
log.Println("rename failed: ", err)
return
}
}
m := &SuccessMessage{
Id: msg.Id,
Task: "map",
}
emptyReply := FinishTaskReply{}
if ok := call("Coordinator.FinishTask", m, &emptyReply); !ok { // 通知Map任务完成
println("Coordinator exit")
return
}
case REDUCE:
paths, err := filepath.Glob(fmt.Sprintf("mr-intermediate-*-%d", msg.Id)) // 根据Coordinator指定参数获取键值对
if err != nil {
log.Println("failed to fetch files from reduce")
}
data := make(map[string][]string) // 读入内存
for _, p := range paths {
f, err := os.Open(p)
if err != nil {
log.Println("failed to open reduce source: ", err)
return
}
kv := KeyValue{}
decoder := json.NewDecoder(f)
for {
err := decoder.Decode(&kv)
if err != nil {
if errors.Is(err, io.EOF) {
break
}
log.Println("json decode failed: ", err)
f.Close()
return
}
data[kv.Key] = append(data[kv.Key], kv.Value)
}
f.Close()
}
keys := make([]string, len(data))
i := 0
for k := range data {
keys[i] = k
i++
}
slices.Sort(keys) // 按key排序逐个处理
tmp, err := os.CreateTemp(".", "tmp-mr-out-*")
for _, k := range keys {
res := reducef(k, data[k]) // 对每组键值对调用Reduce函数
if err != nil {
println("reduce write failed: ", err)
tmp.Close()
return
}
_, err = fmt.Fprintf(tmp, "%v %v\n", k, res)
if err != nil {
println("reduce write failed: ", err)
tmp.Close()
return
}
}
tmp.Close()
err = os.Rename(tmp.Name(), fmt.Sprintf("mr-out-%d", msg.Id))
if err != nil {
log.Println("rename failed: ", err)
return
}
m := &SuccessMessage{
Id: msg.Id,
Task: "reduce",
}
var emptyReply FinishTaskReply
if ok := call("Coordinator.FinishTask", m, &emptyReply); !ok { // 通知Reduce任务完成
println("Coordinator exit")
return
}
}
}
}Map任务产生的中间文件按 "mr- 命名,便于Reduce任务根据自身Id遍历 intermediate-{MapTaskId}-{ReduceTaskId}""mr-intermediate-*-{ReduceTaskId}" 读取。
NReduec不一定是调用Reduce函数的次数,而是执行Reduce工作的Worker个数。此处通过
hash(key) % NReduce将键值对分组存储,但后续调用reduce时,依然是将键相同的键值对作为参数传入的。
Part2 Coordinator调度Worker
Coordinator作为服务器,记录任务状态并安排任务。
// 安排任务
type AssignMessage struct {
Id int
Task Task
Info string
NReduce int
}
func (c *Coordinator) AssignTask(args *AssignTaskArgs, reply *AssignMessage) error {
reply.NReduce = c.NReduce
c.rwMux.Lock()
defer c.rwMux.Unlock()
if c.mapTasksFinished < len(c.MapTaskRecord) { // Map任务未全部完成
reply.Task = MAP
for i, state := range c.MapTaskRecord { // 遍历检查可以安排的任务
if ShouldStart(state.Status, state.StartTime) {
reply.Id = i
reply.Info = state.File
c.MapTaskRecord[i].Status = PROCESSING // 更新任务状态
c.MapTaskRecord[i].StartTime = time.Now() // 更新任务开始时间
return nil
}
}
reply.Task = WAIT // 若无可进行的任务,说明有Map任务还未完成,先等待
return nil
}
if c.reduceTaskFinished < c.NReduce { // 安排Reduce任务
for idx, state := range c.ReduceTaskRecord {
if ShouldStart(state.Status, state.StartTime) {
reply.Task = REDUCE
reply.Id = idx
c.ReduceTaskRecord[idx].Status = PROCESSING
c.ReduceTaskRecord[idx].StartTime = time.Now()
return nil
}
}
reply.Task = WAIT
return nil
}
reply.Task = EXIT
return nil
}
func ShouldStart(status Status, startTime time.Time) bool {
return status == WAITING || (status == PROCESSING && time.Since(startTime) > 10*time.Second)
} // 任务未开始/任务10秒仍未完成,判定任务失败,应该将任务重新分配到新的Worker
func (c *Coordinator) FinishTask(args *SuccessMessage, reply *FinishTaskReply) error {
c.rwMux.Lock()
defer c.rwMux.Unlock()
switch args.Task { // 任务完成,更新状态
case MAP:
if c.MapTaskRecord[args.Id].Status == PROCESSING {
c.MapTaskRecord[args.Id].Status = FINISHED
c.mapTasksFinished++
}
case REDUCE:
if c.ReduceTaskRecord[args.Id].Status == PROCESSING {
c.ReduceTaskRecord[args.Id].Status = FINISHED
c.reduceTaskFinished++
}
}
return nil
}失败重试逻辑存在问题。若某项任务耗费时间超过10s,该任务被重新分配后,先前的Worker又正确完成任务,后来的Worker也正确完成任务,则会导致任务被重复完成。考虑Coordinator为单个任务的每次尝试维护一个“版本号”,确保只有最新的任务完成被视作有效完成。
还可以引入最大重试次数,若重试次数过多则判定整个MapReduce任务失败。
总结
- MapReduce通过单一Coordinator和超时重试,用简单清晰的方式实现了有容错、易扩展的并行计算。
- 与常规的多线程任务划分策略不同,MapReduce先将原始数据转化为键值对,再按键值对分组处理,提升了框架的灵活性和通用性。
MapReduce: Simplified Data Processing on Large Clusters
https://pdos.csail.mit.edu/6.824/papers/mapreduce.pdf





好可爱的封面~恭喜楼主又得到一次锻炼自己的机会呀ଘ(੭ˊᵕˋ)੭* ੈ✩
严肃看不懂
多线程也可以这样划分任务,试试用c语言的pthread库实现一个多线程版本就懂了٩(ˊᗜˋ*)و